Cross-cultural structures of personal name systems reflect general communicative principles
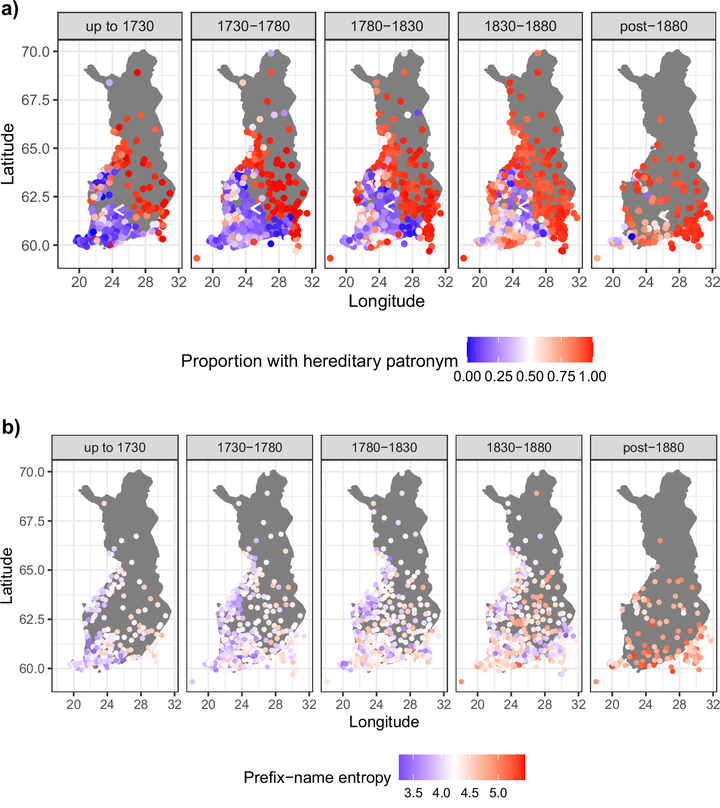 Image credit: Nature Communications
Image credit: Nature Communications
Abstract
The structure of personal names appears to differ widely across cultures. Using census records and historical datasets, we present an information-theoretic analysis of name systems that shows how the scope of this variation is more constrained than it might appear. We identify two constraints name systems must satisfy: encoding large numbers of identities, and ensuring these encodings are usable. We show that, historically, the world’s languages satisfied these constraints using structurally similar, near-optimal codes. They did so by combining sets of name-specific words with existing vocabulary items, allowing unlimited numbers of identifiers to be created while keeping vocabulary sizes stable. Today, many natural name systems have been transformed into official codes based on hereditary patronyms. We show how, globally, these changes differentially altered the information structure of codes, leading to cross-cultural differences in the way names function as individuators that can have tangible effects in domains like scientific publishing.